tlCorpus is a comprehensive application designed for linguists, terminologists and other language professionals, providing them with the means to create an extensive language corpus to work with.
A language corpus is made up of numerous pieces of authentic text, useful especially for studying the changes that occur in a language and the frequency or disappearance of certain words in written or spoken language, but it also provides insight into the culture and history of a particular nation.
In order to offer true answers about such issues, a language corpus requires large amounts of text, specifically so it can draw its conclusions from multiple sources. As such, language enthusiasts will find various purposes it. For instance, a terminologist can use it to quickly generate a term list, that can gradually be developed into a term base.
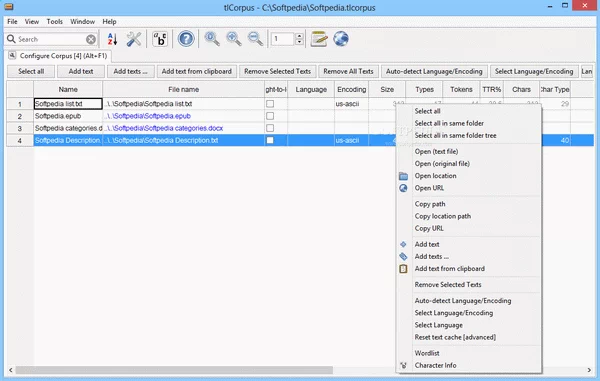
tlCorpus allows users to paste text from clipboard or add it by importing various files. The supported formats are quite numerous, such as HTML, TXT, DOC, DOCX, PDF, RTF, CHM, MOBI, EPUB or POS. This ensures the use of authentic texts as well as an coverage of several fields of human activity.
tlCorpus enables users to automatically generate word lists from the imported documents, which can then be saved to TXT format and used in other purposes. Such a file also contains the usage frequency for each extracted word.
Moreover, the 'Auto-detect Language' function allows users to quickly identify a language that is not familiar to them. It can create text databases of up to 4GB, providing its users with more than sufficient space to compile every piece of information they need.
tlCorpus is a great utility, as it offers users professional tools for analyzing languages and generating word lists, in an efficient and reliable manner, saving them a lot of valuable time.

Related Comments
augusto
Tack för tlCorpus aktivatorMurilo
Thanks a lot for sharing tlCorpus!Abel
grazie mille per il serial